

Want Better Quality Data? Use It Before It’s Perfect!
A Playbook for Building Trust & Improving Data Quality Without Chasing Perfection
I was getting frustrated.
My team had built some genuinely impressive data products for the first time in the company’s history.
But… they wouldn’t release them to the users.
Every time I asked why, I got the same answer:
“We want to make sure data quality is right.”
“We’re still reconciling the data against the legacy reports.”
“If we release the data now and something data is wrong, users will lose trust.”
They were being overly cautious.
Chasing perfection had gotten in the way of progress.
They had convinced themselves that the data had to be 100% accurate before release, whereas users were happy with ‘good enough’ data now, and improvements on an ongoing basis.
Signal from Noise
Here's what I've learned from years of shipping data products:
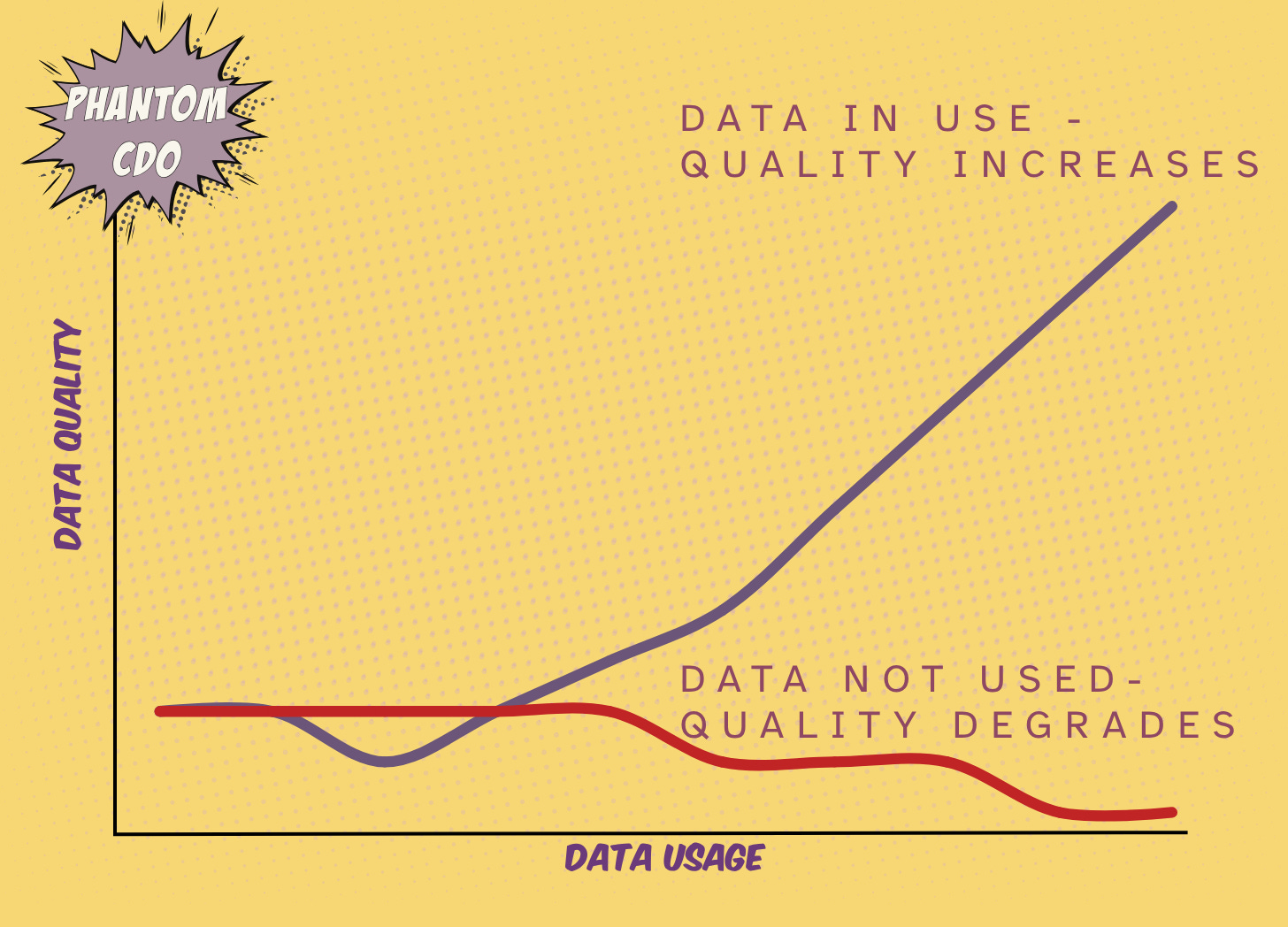
Unused data decays — if data gets used, problems with the data gets surfaced and fixed, which improves quality and usefulness of data
Perfect data quality is a Myth — data quality doesn’t need to be 100%, it needs to be fit-for-purpose for the use case
Data quality is a shared responsibility — of the data team and the users of data
Behind the Dashboard
There’s a comforting lie data teams tell themselves:
“We can’t release it yet. It’s not ready. We need to make sure data is 100% accurate.”
I get it.
No one wants to be on the hook for publishing wrong numbers.
But reality is the longer you wait to release data, the less your users trust you.
Here’s the paradox:
The only way to make data trustworthy… is to put it in front of users.
Data usage will surface issues in the data, and you can use this feedback to fix the problem. Different usage patterns will give you more/different data quality rules to apply, broadening the use of data. When users use data to drive real business decisions, you will understand what works and what doesn’t.
That’s how trust in data is built. Not by hiding the data until it’s flawless — but by exposing it and improving it iteratively.
Playbook || Data -> Insights -> Action
Here’s a brief playbook I’ve developed you can use to get value from data early and iteratively, improve data quality the right way and gain user trust along the way.
Release early & often. Be transparent on state of the data
Don’t wait for perfection — launch your data products early but include explicit & visible data quality indicators
Include clear labels like “Not suitable for regulatory reporting” or "Beta - reconciliation in progress”. My preferred approach is to implement a traffic light system in dashboards & data catalog - Green for production-ready, Yellow for "use with caution," Red for "exploratory only”.
Explicitly communicate known gaps to set expectations and protect trust.
Define quality in business terms, not technical ones
Co-define what “high quality” data means with end users: availability? relevance? frequency? actionable? interpretable?
Prioritise fixing data that directly drives business decision & outcomes
Include quality indicators (e.g. “last updated,” “source system delay”) directly in your data products
Match data controls to criticality and risk profile
Define tiers of data assurance and apply controls proportionally — not all data deserves military-grade validation
Use lightweight governance & controls for exploratory or low-risk products
Provide clear guidelines on what not to use the data for e.g. ‘Do not use for regulatory reporting, dataset not certified”
Share results of data controls testing with users
Establish seamless feedback loops
Make it easy for users to report issues without friction — use tooling to capture, track and make data issues transparent to users
Treat users as collaborators — enlist them in identifying data issues & prioritizing fixes
Communicate fixes and iterations publicly to build trust
Focus on fixing data quality issues, not just detection
Implement processes to fix data issues at the source where possible — partner with upstream owners to correct root causes, not just patch symptoms downstream.
Assign ownership of data issues and track SLAs — ensure recurring issues have clear accountability and defined resolution timelines.
Communicate improvements visibly & make progress easy to see — frequently share what’s been fixed and improvements, and also areas where you need support to implement fixes
Make quality a shared responsibility
Assign data ownership across the pipeline — The central data team alone cannot be responsible for fixing data issues. Identify upstream creators of data, their leaders and data owners, and make them equally responsible for data quality.
Build shared incentives — align and equip business, ops, and tech teams to understand and act on the real-world impact of poor data quality.
Embed data quality as a business KPI & make it a standing item in operational reviews. In your data quality dashboards, include the ‘so what’ to articulate impacts of data issues on business operations.
Conclusion
You don’t earn trust by hiding data until it’s flawless. You earn it by releasing it to users early with transparent messaging on its state, enlisting users to help identify issues, fixing what matters to them, and showing progress over time.
Perfection is a trap. Choose Pace over Perfection!